テキストマイニングとは?種類や目的・活用例や成功させるポイントを詳しく解説
-
- カテゴリ
- カテゴリー1
-
- 公開日
- 2024.03.29
テキストマイニングを実施することで顧客ニーズの把握やトレンド予測などができるため、マーケティング活動や業務効率化に役立ちます。SNSやWebサイトなどのテキストデータを分析するのに最適です。
本記事では、テキストマイニングの基礎知識や種類、実施する目的や活用例、成功させるポイントなどを詳しく説明します。
テキストマイニングを自社で実施したいと考えている方はぜひ参考にしてください。
目次
テキストマイニングとは
まずはテキストマイニングの意味やテキストマイニングとAIの関係を説明します。社内でテキストマイニングを実施するためにも確認しておきましょう。
テキストマイニングの意味
テキストマイニングとは、文章(テキスト)と採掘(マイニング)を結びつけた用語です。テキストマイニングは膨大なテキストデータから有益な情報を取り出すことの総称であり、文章を定量的に扱うための分析手法です。人間の言語をコンピュータで取り扱う自然言語処理(NLP)の進歩により、テキストマイニングの分析精度は向上しています。
テキストマイニングは文章を文節に分割して解析するため、単語の出現頻度を分析し全体像を把握したり、単語の種類別に増加数を解析したりするケースに役立つでしょう。
テキストマイニングの主な分析対象には、X(旧Twitter)やThreadsのようなSNSの投稿、自由記述のアンケート、コールセンターへの問い合わせなどテキストデータがあります。
テキストマイニングとAIの関係
一般社団法人 人工知能学会の定款によると、“人工知能は大量の知識データに対して、高度な推論を的確に行うことを目指したものである。 ”(※)と定義されています。
※引用: 一般社団法人 人工知能学会 定款 – 人工知能学会 (The Japanese Society for Artificial Intelligence)
AIはデータを活用した複雑な思考や判断を目指しています。一方のテキストマイニングは、基となる文章データから必要な情報を抽出・分析し、特定のトピックや傾向を見つけることが主な目的です。このように両者には明確な違いがあります。
一方でAIはテキストマイニングに大きな影響を与えています。AI技術の進歩により、従来は困難だったテキストマイニングが容易になってきているのです。解析対象のデータが増えたことで単語の類似性の精度が向上し、文章全体の類似性を発見しやすくなっています。
テキストマイニングと似た用語との違い

テキストマイニングと混同されやすい用語として「データマイニング」「アフターコーディング」があります。テキストマイニングとの違いについて確認しておきましょう。
データマイニングとの違い
テキストマイニングとデータマイニングでは、対象とするデータの範囲が異なります。
データマイニングは統計学や人工知能などの技術を活用し、膨大なデータから有益な情報を見つける手法の総称です。売上情報の分析で実施した場合は、時間帯ごとの商品が売れる相関関係を分析できます。データマイニングは文書だけでなく、画像や動画なども対象になるため、テキストマイニングより対象範囲が広いという特徴もあります。
テキストマイニングはデータマイニングの一種であり、主にSNSや記述式アンケートなどの文書から、サービスの課題や顧客の口コミを把握できるという違いがあります。
アフターコーディングとの違い
テキストマイニングとアフターコーディングでは、目的や手法が異なります。
アフターコーディングとは、アンケートに含まれる自由記述を数量的かつ視覚的に整理する手法です。自由記述の内容をカテゴリごとに分け、コード化してデータ処理を行います。
アフターコーディングとテキストマイニングは異なるアプローチです。アフターコーディングが定性的な情報を定量的かつ視覚的に整理する方法である一方、テキストマイニングは文章中の単語やフレーズを重点的に分析して整理します。
テキストマイニングの種類は主に2つ
テキストマイニングの主な種類として「探索的データ解析」「文書分類」の2つがあります。それぞれ解説するので参考にしてください。
1. 探索的データ解析
探索的データ解析とは、未知の情報や不正確な質問の答えを探るデータマイニングです。
探索的データ解析では、テキストを単語や文節で区切る形態素解析が用いられます。単語に分解・解析した上で、時系列変化や出現頻度といった情報を抽出する手法です。
探索的データ解析だけがテキストマイニングの手法と思われがちですが、実際はテキストマイニングの範疇に探索的データ解析が含まれています。
2. 文書分類
文書分類はテキストデータの内容をもとに分類するデータマイニングの手法です。定義済みのテキストデータから新たな傾向や法則を見つけ出し、特定の目的に応じて活用します。
また、文書分類は大きく「教師あり文書分類」と「教師なし文書分類」の2種類に分かれます。
教師あり文書分類とは、分類器によって外部の情報を参照して分ける方法です。分類器とは、事前にテキストとテキストを振り分けるクラスとの関係性を学習させたものです。教師あり文書分類には学習と分類の2つの段階があり、多くの学習が行われた結果、分析精度が向上します。
教師なし文書分類とは、外部の情報を参照せず、クラスタリングによって分類する方法です。クラスタリングとは、テキストを類似する特徴に基づいて分類する手法です。
テキストマイニングを実施する4つの目的

テキストマイニングを実施する目的として以下の4つが挙げられます。
- 顧客の心理やニーズを把握する
- 業務課題を調査・改善策を見出す
- トレンドを予測する
- ネガティブな情報・キーワードを抽出する
それぞれ解説していきます。
1. 顧客の心理やニーズを把握する
自社の商品やサービスに関する顧客からの意見、要望、アンケート内容などをテキストマイニングによって分析可能です。多角的に顧客の心情を理解できるため、ニーズの明確化につながるでしょう。
視認による顧客心理の把握は、自分の考えを軸にした主観的な分析結果になりかねません。しかしテキストマイニングを活用することで数値に基づいた分析が可能です。主観を排除し、テキストデータから客観的な情報を引き出せます。
また、商品やサービスの売り上げが低迷している場合も、顧客の意見から原因を明らかにしやすくなります。テキストマイニングによって売上不振の原因をスムーズに特定し、改善策を講じることが可能です。
2. 業務課題を調査・改善策を見出す
テキストマイニングは社内データの調査や改善にも効果的です。たとえば作業報告書、営業日報、レポートなどのテキストデータをテキストマイニングすることにより、業務の問題点や、優れた成績を収めている社員のノウハウを抽出して社内で共有できます。これにより業務の属人化が解消され、優秀な社員の知識やスキルの標準化が可能です。
昨今は、AIによる営業日報のテキストマイニングも開始されています。営業担当者の日報をもとに、「どのような営業活動にどれくらい時間を割いたのか」といった活動内容を数値化できるサービスです。
3. トレンドを予測する
テキストマイニングはトレンド予測にも有効なため、自社商品の仕入れ・販売などにも役立ちます。たとえば、SNSに投稿されたコメントやニュース記事を解析することにより、市場や競合他社の動向、消費者ニーズなどを把握できるからです。
このようにテキストマイニングは効果的な経営戦略の実現に活用できます。テキストデータを効果的に活用するには、適切なテキストマイニングツールの実施が重要です。
4. ネガティブな情報・キーワードを抽出する
スマートフォンの所有率増加により、情報拡散のスピードが加速しています。ポジティブな情報がSNSで拡散される反面、爆発的にネガティブな情報が広がる「炎上リスク」も懸念されます。
企業が炎上リスクに対処するには、可能な限り早期に情報を把握し、適切な対策を取らなければなりません。テキストマイニングの活用は、自社に対するネガティブな情報・キーワードを抽出する手法としても役立ちます。
炎上対策にはソーシャルリスニングツールの実施も効果的です。ソーシャルリスニングツールとは、SNSやブログ、レビューサイトなどに投稿された内容を分析できるツールです。アラートメールに対応しているソーシャルリスニングツールは、炎上リスクをメールで教えてもらえるので早期に対応できます。
>>>SNSを監視できるツール15選!活用するメリットや選び方・リスク検知の対応方法を解説
テキストマイニングの活用例

テキストマイニングの活用例には以下があります。
- ソーシャルメディアの情報分析
- チャットボットの精度向上
- 顧客アンケート結果の分析
- 技術文書の動向分析
それぞれ解説するので参考にしてください。
ソーシャルメディアの情報分析
テキストマイニングはX(旧Twitter)やInstagramのようなソーシャルメディアの情報分析に役立ちます。
具体的には、キーワードの使用頻度や時系列に基づく変化、顧客が抱える不満や改善点など、ソーシャルメディア上の膨大なテキストの解析が可能です。それにより、単に自社の商品やサービスを分析するだけでなく、将来のマーケティングに不可欠な顧客ニーズを把握できるというメリットがあります。
たとえば、積極的な販促活動がどの程度、顧客に浸透しているかを客観的に把握できます。自社の商品・サービスを顧客が想起する状況も分析できるでしょう。
チャットボットの精度向上
テキストマイニングはチャットボットの精度向上に利用されます。チャットボットとは、顧客の問い合わせに対して自動で回答するツールです。
従来、顧客が「商品やサービスの不明点を解決したい」と考えた場合、コールセンターへの問い合わせやFAQコンテンツの確認が一般的でした。しかし、コールセンターへの問い合わせをしても時期や時間帯によってつながりにくかったり、FAQコンテンツを調べる手間がかかったりということに不満を抱く顧客も少なくありません。
チャットボットを活用すれば、顧客は単語や文章を入力するだけでスムーズに回答を得られるため、顧客満足度の向上が見込まれます。テキストマイニングをチャットボットに活用することにより、顧客が入力した検索ワード、課題解決の割合、解決に至らなかった質問事項なども分析可能です。その結果、チャットボットの応答精度向上が期待できます。
顧客アンケート結果の分析
多くの企業は商品・サービスの品質やセミナー評価を向上させるため、顧客向けのアンケートを定期的に行っています。しかし従来は企業の担当者が手動でアンケートを集計し、エクセルのようなツールで数値をまとめるケースが大半でした。
テキストマイニングで顧客アンケートを効率的に分析することにより、大幅な時間短縮が可能です。また、従来の定量データ(集計可能なデータ)だけでなく、定性データ(心理的なデータ)をもとにアンケートを分析し、顧客ニーズを発掘できるという特徴もあります。
技術文書の動向分析
技術文書の分析でもテキストマイニングは使用されています。論文や特許などの技術文書は専門用語の多さや、他の技術文書との関連性を理解しづらいという問題があります。しかしテキストマイニングを実施することにより、効率的な分析が可能です。
たとえば、単語や語句の使用頻度を把握すれば、今後のマーケティング活動に活用できるかもしれません。競合他社の特許状況を分析することにより、他社が特許を取得した商品の内容がわかるため、投資傾向や新規事業も予測できるでしょう。
テキストマイニングの主な手法

テキストマイニングの主な手法には以下があります。
- センチメント分析(感情分析)
- 対応分析(コレスポンデンス分析)
- 主成分分析(PCA)
- 共起分析
それぞれ解説していきます。
センチメント分析(感情分析)
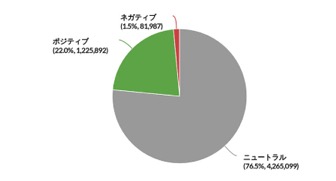
※出典:SNS分析サービス | Quid Monitor(旧NetBase) – TDSE株式会社
センチメント分析(感情分析)とは、テキストに含まれる顧客や消費者の感情を分析する方法です。
SNSの投稿やブログ記事などの情報からユーザーの感情を分析します。それにより、商品やサービスの課題発見、マーケティング戦略の策定、商品開発などに活用できます。
センチメント分析はポジネガ分析と呼ばれることもあり、「肯定的」「中立」「否定的」の3つのパターンに分類するのが一般的です。ただし分析対象の言葉によっては、「肯定的」とも「否定的」とも受け止められるため、機械的な分析が難しいという側面があります。
センチメント分析は主に顧客満足度の測定や新製品のテスト、広告のターゲティングなどで活用される分析方法です。
対応分析(コレスポンデンス分析)
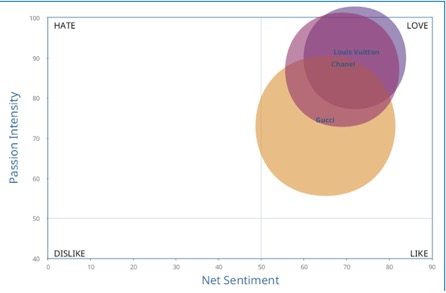
※出典: ブランドエクイティ(資産価値)の維持・測定事例 – ルイ・ヴィトン社| 海外SNS活用事例 | Quid Monitor(旧NetBase) – TDSE株式会社
対応分析(コレスポンデンス分析)とは、 リサーチやアンケートの結果を散布図によって可視化する分析手法です。散布図とは、特定のデータを縦軸と横軸の2つの項目で計測し、分布の度合いを視覚的に表現したグラフのことです。
対応分析の主な目的として、集計項目や分類項目の関係性の把握が挙げられます。たとえば、自社と競合他社に対するブランドイメージや、ポジショニングの違いを可視化する目的で利用されます。
このように対応分析は、異なる項目同士の差異や類似性の比較に適した手法です。
主成分分析(PCA)
主成分分析(PCA)とは、データ解釈のために可能な限り変数を減らし、データを簡潔にまとめて提示する分析手法です。収集したビッグデータの分析をしやすくするために活用できます。ただし一部の重要度が低い情報は切り捨てられることがあります。
主成分分析はマーケティングやテスト結果の分析など、さまざまな分野で用いられています。マーケティングに関しては顧客の趣向や行動を把握できるため、新たな顧客セグメントの発見につながります。テスト結果の分析では学生の能力を抽出して理解できるため、成績を解釈しやすくなるでしょう。
共起分析
共起分析とは、文章中で使用される単語の使用頻度から、商品やサービスなどを分析する手法です。共起分析を利用することにより、ユーザーが商品を評価する際に使用する言葉を理解できるため、商品の特徴や魅力を推量できます。
たとえば「英会話」に対して、「オンライン」「教室」という言葉の共起分析を考えてみましょう。多数の人が「英会話」に「オンライン」という表現を使用している場合、オンラインで受講できる英会話への関心が高いと予測できます。一方で「教室」という表現が多い場合、ユーザーはオンラインではなく、実際に通える英会話教室に興味があると予測できるでしょう。
このように共起分析を活用することにより、ユーザーが物事を評価する際にどのような印象を抱いているのかを理解できます。
テキストマイニングを実践する4つのステップ
テキストマイニングは以下の4ステップで実践できます。
- 調査対象のデータを収集する
- 分析前のデータ処理を行う
- 構造化データに変換する
- 変換したデータを分析・可視化する
ステップごとに1つずつ解説するので参考にしてください。
1. 調査対象のデータを収集する
最初にテキストマイニングで分析したいデータを収集します。対象となるデータには、SNSの投稿、サイトやブログ記事、アンケート、メール、顧客からの問い合わせ履歴などがあります。
実際にデータ収集を実施する際は、テキストマイニングの目的に沿ったデータ選定が大切です。たとえば、顧客から自社に寄せられたフィードバックを把握したい場合は、問い合わせ履歴やアンケートなどのデータを収集します。ネット上にある商品やサービスのレビューを分析したい場合は、SNSの投稿やレビューサイトからデータを収集しましょう。
また、テキストマイニングは文章中の単語が解析対象になるため、大量にテキストデータを収集する必要があります。収集するデータが多ければ多いほど、より正確な分析結果を期待できます。
2. 分析前のデータ処理を行う
テキストマイニングの精度を上げるにはデータの前処理が必要です。具体的な方法として、文章を単語に分割した上で各単語の出現数をカウントします。品詞の分解、誤字脱字の修正、不要な文字の削除なども行います。
ただしテキストマイニングツールは、文章データそのものを理解しません。特に「あれ」「それ」といった指示語や、「ないというわけではない」といった二重否定には注意が必要です。
3. 構造化データに変換する
分析前に処理したデータ(非構造化データ)を構造化データに変換します。
非構造化データとは列と行の構造に該当しないデータのことです。文章データも非構造化データに当てはまります。このような非構造化データのままでは、コンピュータによる分析は困難です。
対照的に構造化データとは、列と行の構造を持つデータのことです。気象データやエクセルでまとめた事例などが当てはまります。構造化データに関してはコンピュータによる分析が可能です。ただし手動による構造化データへの変換は手間がかかります。スムーズに変換を行うには専用ツールの使用が効果的です。
なお、データをコンピュータで分析しやすくするには、データクレンジングも欠かせません。データクレンジングとは、データの重複、誤記、表記揺れなどを検出し、修正や削除、正規化などで処理してデータの品質を高め、最新の状態に整える作業のことです。
4. 変換したデータを分析・可視化する
非構造化データを構造化データに変換した後、特定の目的に基づいた手法を選択した上で分析します。頻度、相関値、トレンド、時系列などが分析の観点です。頻度ではデータ中の要素の出現頻度を検証し、相関値では要素同士の関係性を調査します。トレンドや時系列ではデータの変化や推移を追跡することにより、特定のパターンを捉えられるでしょう。
分析結果や考察を直感的に理解するには、チャート、カラム、グラフといったダッシュボードの活用が効果的です。データの傾向や関係性を可視化できます。そのための手段に時系列分析が挙げられます。
時系列分析とは、時間経過によって変化するデータの分析のことです。たとえば、店舗への来客数や日々の売上金額などが時系列分析の対象となります。
テキストマイニングに活用できる3つのツールと方法

テキストマイニングに活用できるツール・方法には以下の3つがあります。
- Excel(エクセル)の活用
- プログラミング言語の活用
- テキストマイニングツールの活用
それぞれ解説するので参考にしてください。
1. Excel(エクセル)の活用

エクセルは代表的な表計算ツールであり、多くの人が使い慣れているため、気軽にテキストマイニングを試せます。特に簡単な分析に向いている方法です。
実際にエクセルで分析する流れとして、最初にデータ収集を行った後、文章の単語化(形態素解析)、SUM関数やCOUNTIF関数などによる単語の整理・集計、グラフや表機能を利用した視覚化という順序で進めます。
ただし、エクセルは取り扱えるデータ量に制限があるという点に注意が必要です。大量のデータを扱う場合は後述するテキストマイニングツールの実施を検討してください。
2. プログラミング言語の活用

PythonやRなどのプログラミング言語を活用することにより、テキストマイニング用のプログラムを作成できます。その場合、MeCabのような外部ツールの使用が一般的です。
プログラミング言語は柔軟にカスタマイズできるというメリットがあります。ただしプログラミングに関する専門知識やスキルが必要です。事前にプログラミングスキルに秀でた社員を確保する必要があるものの、特定の人材に依存しすぎると属人化しやすいので注意してください。
すでに自社でプログラミングスキルが高い社員が活躍していて、詳細な条件を設定してテキストマイニングを行いたい場合におすすめの方法です。
3. テキストマイニングツールの活用
テキストマイニングツールとは、SNSやレビューサイト、カスタマーセンターでの顧客対応、アンケートなど膨大なテキストデータから必要な情報の抽出・分析を行い、結果を可視化できるシステムです。エクセルよりも詳細な分析が可能であり、プログラミングスキルがなくても気軽に活用できるため、多数の企業がテキストマイニングツールを利用しています。
一部のテキストマイニングツールは無料で提供されていますが、有料ツールよりも機能が限定的です。有料ツールは通常、高度な分析やカスタマイズに対応しているので目的や予算に合わせて選ぶとよいでしょう。
テキストマイニングツールの選び方に関しては次項で詳しく解説します。
テキストマイニングツール選び方4つのポイント
テキストマイニングツールの選び方には4つのポイントがあります。
- ニーズに合った機能を備えているか
- 操作しやすいか
- 分析精度や処理速度はどうか
- 辞書機能が充実しているか
それぞれ解説していきます。
1. ニーズに合った機能を備えているか
テキストマイニングツールを選ぶ際は、自社のニーズに合った機能に対応しているかどうかが重要です。特にSNS、ブログ、レビューサイトなど、分析したいコンテンツや情報源で検索できるかどうかを確認しましょう。
また、固有名詞や専門用語の登録機能があれば、キーワードを事前に登録できるので分析精度や作業効率の向上が期待できます。分析結果の可視化機能を備えていれば、図表やグラフで視覚的に表示できるため、データの傾向や関係性をスムーズに把握できます。
2. 操作しやすいか
テキストマイニングツールは繰り返し操作することになるため、操作性も重視してください。ツール利用時の画面や分析結果が見やすければ、分析担当者以外の社員も直感的に利用できます。
基本的には、ITに苦手意識があっても簡単に操作できるツールがおすすめです。有料ツールによっては無料トライアル期間があるため、事前に操作性を試してから実施を検討できます。
3. 分析精度や処理速度はどうか
テキストマイニングツールの実施目的は精度の高いデータ分析です。そのためには単語の抽出や意味の解析が適切に行われ、正確な結果を得られるかどうかの確認が大切です。
また、テキストマイニングでは大量のテキストデータを扱います。処理速度が速ければ膨大なデータを素早く分析できるため、作業効率がアップします。したがってテキストマイニングツールを実施する前に処理速度の確認を行いましょう。
4. 辞書機能が充実しているか
辞書機能とは、商品名やサービス名などの固有名詞や専門用語を事前に登録できる機能です。テキストマイニングツールに辞書機能が組み込まれている場合、正確な単語の抽出や用語の統一性が期待できるため、分析精度の向上につながります。
一部のテキストマイニングツールには新語や流行語を自動登録する機能も備わっており、辞書更新の作業負担を軽減できます。特に活用目的や商品種別に応じて条件を設定できるテキストマイニングツールがおすすめです。業界や業種に特有の表現やキーワードに対応できるため、分析作業が効率化します。
テキストマイニングの実施を成功させる2つのポイント

テキストマイニングの実施を成功させるポイントとして、分析結果の社内共有とPDCAサイクルの継続があります。それぞれ解説するので参考にしてください。
1. 分析結果は社内に共有する
テキストマイニングの分析結果は可視化して社内で共有することがポイントです。主な可視化の方法には以下があります。
- ワードクラウド
- ネットワーク
- パースペクティブ
ワードクラウドは単語の出現頻度に応じて文字の大きさを変えて表示する方法です。重要な単語ほど大きく表示するという特徴があります。
ネットワークはテキストの単語同士の関連性を視覚的に図示する方法です。単語と単語の関連度合いも示せます。
パースペクティブは単語を属性によってマッピングした後、パターンを見出す方法です。
上記3つの方法は数値データよりも直感的に理解しやすいため、マーケティング活動や商品・サービスの改善策に反映させやすいでしょう。
2. PDCAサイクルで繰り返す
テキストマイニングの効果を最大化するには、PDCAサイクルの継続が重要です。PDCAサイクルとは、Plan (計画)、Do(実施)、Check(評価)、Act(改善)の頭文字を取ったものであり、主にビジネスシーンで使用されるフレームワークです。
テキストマイニングを実施した後、課題や改善点を解決するためのPlan (計画)を立てます。次に計画に基づいた施策をDo(実施)した後、再度テキストマイニングを行い、計画通りに進んだかどうかをCheck(評価)します。Act(改善)が必要であれば改善し、再びテキストマイニングを実施するという流れです。
PDCAサイクルを繰り返すことにより、効果的なテキストマイニングが期待できます。
SNSの投稿データ・レビューのテキストマイニングには『KAIZODE』の活用がおすすめ
テキストマイニングは文章を定量的に扱う分析手法です。実施する目的として、顧客心理やニーズの把握、業務課題の調査と改善、トレンド予測、ネガティブな情報・キーワードの抽出があります。テキストマイニングの実施後は、分析結果の社内共有とPDCAサイクルを継続しましょう。
SNSの投稿データ・レビューのテキストマイニングを行うなら、『KAIZODE』の利用がおすすめです。SNSの投稿データ・レビューから消費者の感情を分析し、インサイトに繋がるかを基準に6段階で評価します。消費者が商品やサービスへの言及内容も分析することが可能です。データはあるが分析・示唆を出すための時間が取れないマーケターにおすすめのツールです。
また、リアルタイムでSNS・クチコミの分析したい場合は、『Quid Monitor』の利用がおすすめです。豊富なデータソースの中から消費者のトレンドや流行を分析できるため市場動向の予測、新商品開発に活用可能です。テキストだけでなく、画像分析にも対応しているためテキストマイニングよりも詳細な分析が可能です。
マーケティングご担当者の業務効率化に最適なツールです。ぜひお気軽にお問い合わせください。
もっとKAIZODEを
知りたい方へ
詳しい機能や価格を知りたい方は、右のこの
フォームからお問い合わせください。
サポート内容に関しましても
お気軽に問い合わせください。